simpletrie
![]()
![]()
simpletrie is a simple trie implementation
in plain R code.
A trie is a structure for representing certain data as a tree of nodes. This data representation allows for fast queries of certain types.
simpletrie can build a trie from 175k words in about 3s.
What’s in the box
trie_create()- create a trie, and optionally initialise with a dictionary of wordstrie_insert()- insert words into a trietrie_find_subwords()- find all sub-words in the trie using the characters in the given word
Installation
You can install from GitHub with:
# install.package('remotes')
remotes::install_github('coolbutuseless/simpletrie')Example: Finding sub-words from a given word
My main use-case for simpletrie is for looking up scrabble words i.e. to find all possible sub-words of a given word with:
- the characters in any order
- being able to specify a wildcard to indicate that any letter can be used
i.e. the
.character
library(simpletrie)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Read the ENABLE word list
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
words <- tolower(readLines("enable1.txt"))
length(words)
[1] 172821
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Create trie strcture
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
system.time({
trie <- trie_create(words)
})
user system elapsed
1.762 0.049 1.820
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Find all words which can be made with 'hi.rstats'
# '.' is a wildcard, and can match any letter. (Like a blank tile in scrabble)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
system.time({
subwords <- trie_find_subwords(trie, 'hi.rstats')
})
user system elapsed
0.109 0.003 0.113
length(subwords)
[1] 2304
head(subwords, 100)
[1] "hi" "hire" "hires" "his" "hist" "hists"
[7] "hists" "hiss" "hisser" "hissy" "hisn" "hiss"
[13] "hist" "hists" "hit" "hits" "hitter" "hitters"
[19] "hits" "hiatus" "hic" "hid" "hie" "hies"
[25] "hilt" "hilts" "hila" "hilar" "him" "hin"
[31] "hins" "hint" "hints" "hip" "hips" "his"
[37] "hiss" "hist" "hists" "hit" "hits" "ha"
[43] "hair" "hairs" "hairs" "hairy" "haik" "haiks"
[49] "hail" "hails" "hair" "hairs" "harsh" "hart"
[55] "harts" "harts" "harass" "hard" "hards" "hare"
[61] "hares" "hark" "harks" "harl" "harls" "harm"
[67] "harms" "harp" "harpist" "harpists" "harps" "hart"
[73] "harts" "has" "hast" "hastier" "hastiest" "haste"
[79] "hastes" "hasty" "hash" "hasp" "hasps" "hast"
[85] "hat" "hats" "hatter" "hatters" "hate" "hater"
[91] "haters" "hates" "hath" "hats" "haar" "haars"
[97] "habit" "habits" "had" "hadst" What’s a trie?
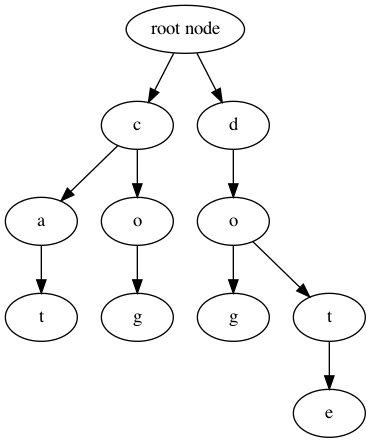
A trie is an ordered data structure represented as a tree of nodes.
The image below shows a very small trie which represents the words: ‘cat’, ‘cog’, ‘dog’ and ‘dote.’
This representation allows for very fast queries of certain types.
Technical bits
The trie is implemented here as nested environments. Environments are
created with new.env(parent = emptyenv(), hash = FALSE).
Using the emptyenv() as parent saves some memory, as the parent
environment is never needed in this process.
hash is set to FALSE as using a hash table expands the memory
usage by quite a bit - even if size is set to limit the initial hash
table size.
Using a hash table on the environment doesn’t appreciably change the speed of trie creation or preforming look-ups.
Environments are used instead of lists as I make use of the reference semantics of environment objects when building the trie.
Acknowledgements
- R Core for developing and maintaining such a wonderful language.
- CRAN maintainers, for patiently shepherding packages onto CRAN and maintaining the repository