xxhashlite
![]()
![]()
![]()
xxhashlite provides simple access to the extremely fast hashing functions
in xxHash for in-memory hashing
of R objects.
This new version of xxhashlite (v0.2.0) is a major update which now offers fast
hashing of any R object by internally leveraging R’s serialization capabilities.
This package is a wrapper around xxHash v0.8.0.
See LICENSE-xxHash
for the copyright and licensing information for that code. With this latest
version of xxHash, the new (even faster) hash functions, xxh3_64bits and
xxhash128, are considered stable.
What’s in the box
xxhash(robj, algo)calculates the hash of any R object understood bybase::serialize().
Installation
You can install from GitHub with:
# install.package('remotes')
remotes::install_github('coolbutuseless/xxhashlite)Installation - set CFLAGs for optimised executable
To get the most out of what xxHash offers, it will be important to set
some optimization flags for your machine. The important compiler flags to set
are -O3 and -march=native.
Here are 2 possible ways to do this:
- Copy
src/Makevars.customtosrc/Makevarsre-build package. - Edit your
~/.R/Makevarsto includeCFLAGS = -O3 -march=native(this will change flags for all future compilation, and should probably be used with caution)
Why use a hash?
A hash is a way of succinctly summarising the contents of an object in a compact format.
If there are changes to the object (no matter how small) then the hash should change as well.
library(xxhashlite)
xxhash(mtcars)[1] "2c8a35b061878544"# Small changes results in a different hash
mtcars$cyl[1] <- 0
xxhash(mtcars)[1] "06a3bba3891cfe7e"Timing for hashing arbitrary R objects
xxhashlite uses the xxHash family
of hash functions to provide very fast hashing of R objects.
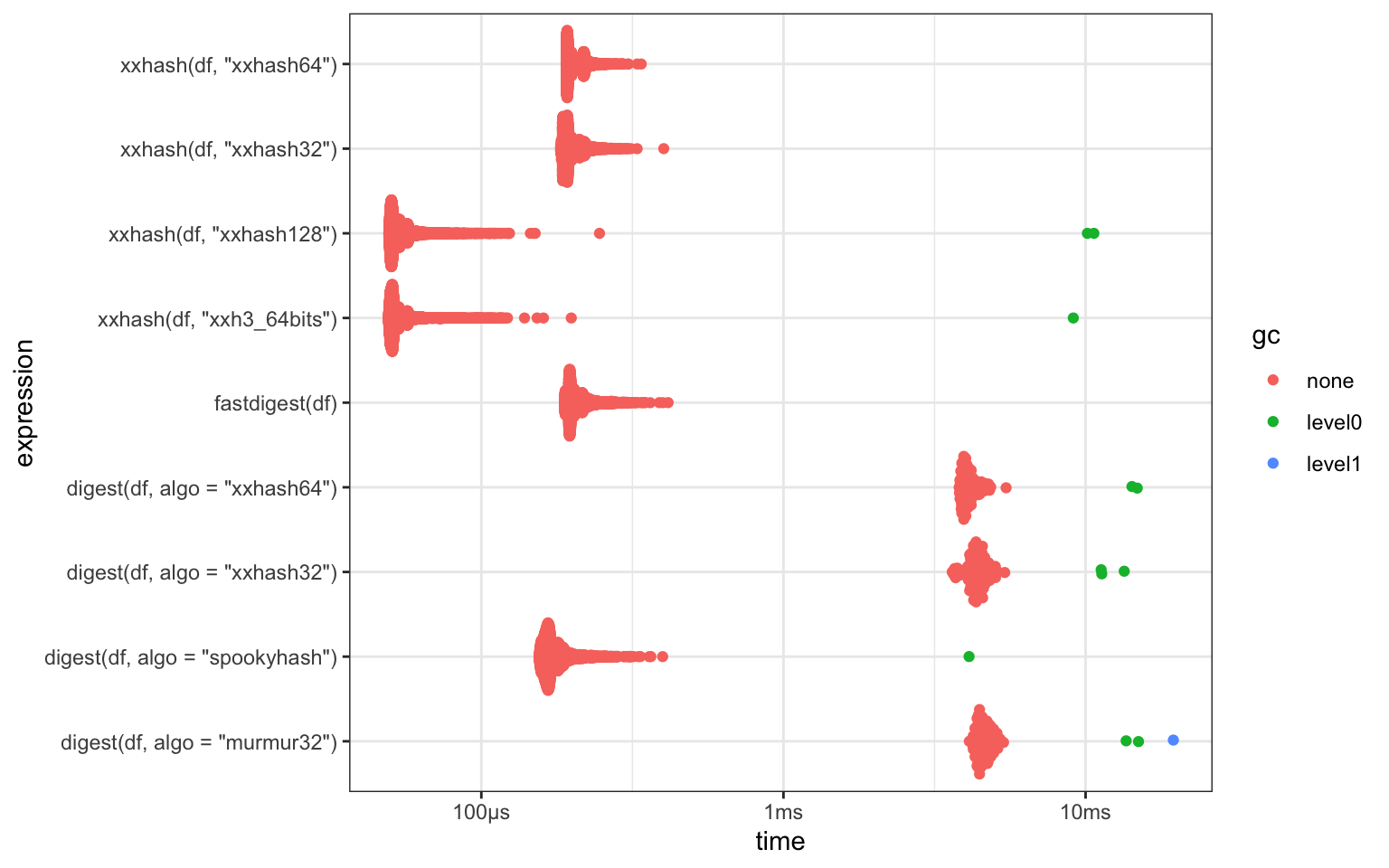
For the test case shown below, xxhashlite is faster at calculating a hash
than all other methods I could find, with a maximum hashing speed in this
specific case of 20 GB/s.
Note: actual hashing speed will still depend on R’s serialization functions e.g. small complex data.frames might have a lot of serialization overhead compared to long numeric vectors.
Click to show/hide the benchmarking code
library(xxhashlite)
library(digest)
library(fastdigest)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Simple data.frame
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
N <- 1e5
df <- data.frame(
x = runif(N),
y = sample(N)
)
size <- pryr::object_size(df)Registered S3 method overwritten by 'pryr':
method from
print.bytes Rcppsize1.2 MBres <- bench::mark(
# {xxhashlite}
xxhash(df, 'xxhash32'),
xxhash(df, 'xxhash64'),
xxhash(df, 'xxhash128'),
xxhash(df, 'xxh3_64bits'),
# {digest}
digest(df, algo = 'xxhash32'),
digest(df, algo = 'xxhash64'),
digest(df, algo = 'murmur32'),
digest(df, algo = 'spookyhash'),
# {fastdigest}
fastdigest(df),
check = FALSE
)| package | expression | median | itr/sec | MB/s |
|---|---|---|---|---|
| xxhashlite | xxhash(df, “xxhash32”) | 193.4µs | 4966 | 5921.5 |
| xxhashlite | xxhash(df, “xxhash64”) | 198.13µs | 4856 | 5780.0 |
| xxhashlite | xxhash(df, “xxhash128”) | 52.68µs | 18247 | 21737.3 |
| xxhashlite | xxhash(df, “xxh3_64bits”) | 51.24µs | 18628 | 22348.8 |
| digest | digest(df, algo = “xxhash32”) | 4.38ms | 227 | 261.4 |
| digest | digest(df, algo = “xxhash64”) | 4.04ms | 242 | 283.1 |
| digest | digest(df, algo = “murmur32”) | 4.58ms | 216 | 250.2 |
| digest | digest(df, algo = “spookyhash”) | 168.88µs | 5643 | 6781.1 |
| fastdigest | fastdigest(df) | 201.69µs | 4741 | 5678.2 |
Acknowledgements
- Yann Collett for releasing, maintaining and advancing xxHash
- R Core for developing and maintaining such a great language.
- CRAN maintainers, for patiently shepherding packages onto CRAN and maintaining the repository