fugly 
![]()
This package provides a single function (str_capture) for using named capture groups to extract values from strings. This function is just a wrapper around stringr.
fugly::str_capture() is very similar to both
unglue
and utils::strcapture().
This package was written because stringr doesn’t yet do named capture groups
(See issues for stringr and
stringi), and I needed something
faster than unglue
| fugly::str_capture | unglue:::unglue | utils::strcapture | |
|---|---|---|---|
| Speed | fastest | slow | faster |
| Naming Groups | inline capture group naming | inline capture group naming | use of prototype to define names |
| Safe + Robust? | dodgy | quite safe | quite safe |
What do I mean when I say fugly::str_capture() is unsafe/dodgy/non-robust?
- It doesn’t adhere to standard regular expression syntax for named capture groups as used in perl, python etc.
- It doesn’t really adhere to
gluesyntax (although it looks similar at a surface level). - If you specify delimiters which appear in your string input, then you’re going to have a bad time.
- It’s generally only been tested on data which is:
- highly structured
- only ASCII
- non-pathological
What’s in the box?
fugly::str_capture(string, pattern, delim)- capture named groups with regular expressions
- returns a data.frame with all columns containing character strings
- can mix-and-match with non-capturing regular expressions
- if no regular expression specified for a named group then
.*?is used. - does not do any type guessing/conversion.
Installation
You can install from GitHub with:
# install.package('remotes')
remotes::install_github('coolbutuseless/fugly')Example 1
In the following example:
- Input consists of multiple strings
- capture groups are delimited by
{}by default. - the regex for the capture group for
nameis unspecified, so.*?will be used - the regex for the capture group for
ageis\d+i.e. match must consist of 1-or-more digits
library(fugly)
string <- c(
"information: Name:greg Age:27 ",
"information: Name:mary Age:34 "
)
str_capture(string, pattern = "Name:{name} Age:{age=\\d+}")## name age
## 1 greg 27
## 2 mary 34Example 2
A more complicated example:
- Note the mixture of capturing groups and a bare
.*?in the pattern which is not returned as a result
string <- c(
'{"type":"Feature","properties":{"hash":"1348778913c0224a","number":"27","street":"BANAMBILA STREET","unit":"","city":"ARANDA","district":"","region":"ACT","postcode":"2614","id":"GAACT714851647"},"geometry":{"type":"Point","coordinates":[149.0826143,-35.2545558]}}',
'{"type":"Feature","properties":{"hash":"dc776871c868bc7e","number":"139","street":"BOUVERIE STREET","unit":"UNIT 711","city":"CARLTON","district":"","region":"VIC","postcode":"3053","id":"GAVIC423944917"},"geometry":{"type":"Point","coordinates":[144.9617149,-37.8032551]}}',
'{"type":"Feature","properties":{"hash":"8197f34a40ccad47","number":"6","street":"MOGRIDGE STREET","unit":"","city":"WARWICK","district":"","region":"QLD","postcode":"4370","id":"GAQLD155949502"},"geometry":{"type":"Point","coordinates":[152.0230999,-28.2230133]}}',
'{"type":"Feature","properties":{"hash":"18edc96308fc1a8e","number":"22","street":"ORR STREET","unit":"UNIT 507","city":"CARLTON","district":"","region":"VIC","postcode":"3053","id":"GAVIC424282716"},"geometry":{"type":"Point","coordinates":[144.9653484,-37.8063371]}}'
)
str_capture(string, pattern = '"number":"{number}","street":"{street}".*?"coordinates":\\[{coords}\\]')## number street coords
## 1 27 BANAMBILA STREET 149.0826143,-35.2545558
## 2 139 BOUVERIE STREET 144.9617149,-37.8032551
## 3 6 MOGRIDGE STREET 152.0230999,-28.2230133
## 4 22 ORR STREET 144.9653484,-37.8063371Simple Benchmark
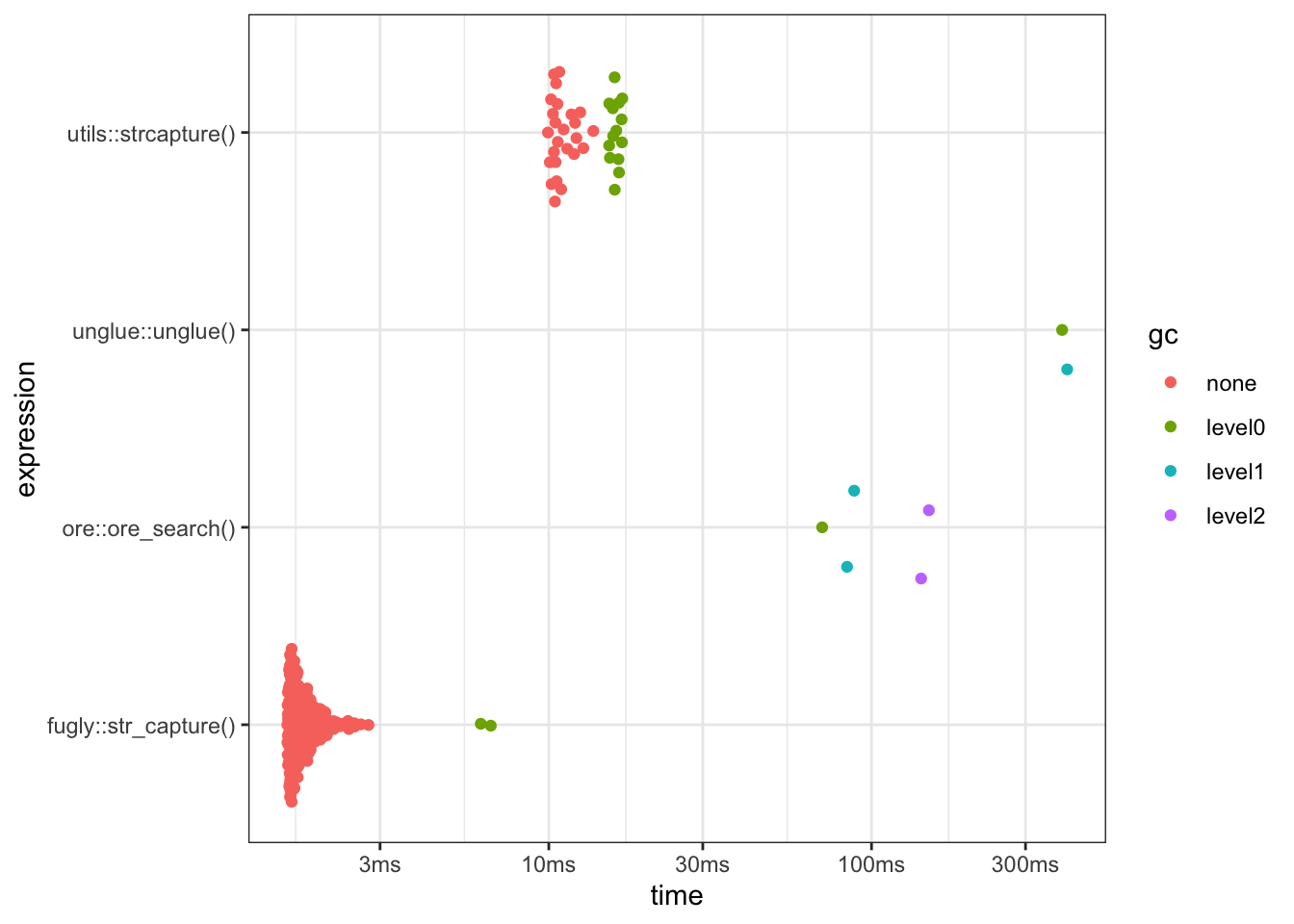
I acknowledge that this isn’t the greatest benchmark, but it is relevant to my current use-case.
- For large inputs (1000+ input strings),
fuglyis the fastest - For small inputs,
fuglyandutils::strcaptureare about equivalent unglueis the slowest of the methods.orelies somewhere betweenunglueandutils::strcapture
# remotes::install_github("jonclayden/ore")
library(ore)
library(unglue)
library(ggplot2)
# meaningless strings for benchmarking
string <- paste0("Information name:greg age:", 1:1000)
res <- bench::mark(
`fugly::str_capture()` = fugly::str_capture(string, "name:{name} age:{age=\\d+}"),
`unglue::unglue()` = unglue::unglue_data(string, "Information name:{name} age:{age=\\d+}"),
`utils::strcapture()` = utils::strcapture("Information name:(.*?) age:(\\d+)", string,
proto = data.frame(name=character(), age=character())),
`ore::ore_search()` = do.call(rbind.data.frame, lapply(ore_search(ore('name:(?<name>.*?) age:(?<age>\\d+)', encoding='utf8'), string, all=TRUE), function(x) {x$groups$matches}))
)
Acknowledgements
- R Core for developing and maintaining the language.
- CRAN maintainers, for patiently shepherding packages onto CRAN and maintaining the repository