Wordles!
Wordles are a word guessing puzzle playable online.
There’s a small write-up in a recent article in The Guardian
The game plays like the old ‘mastermind’ board game, but with letters instead of coloured pins.
- Enter a word as a guess
- Any letters which are within the hidden target word are coloured in yellow.
- Any letters which match exactly the letter in the hidden target word are coloured green
- Figure out a new candidate word as a guess for the hidden target word, and go back to Step 1.
This process of finding strong and weak matches for characters in a word seems quite suited for regular expressions.
The code below is a first rough attempt at generating good candidate guesses to solve Wordle puzzles.
Establish a scoring system for words
At any stage of the game there will be a number of candidate words which match the letters which have been guessed so far. I’ll use an trivial scoring system to determine a priority list of possible next words.
As a rough rule-of-thumb, I’ll score each word by scoring the letters within the word.
Common letters like e and t score low, while q and z score high.
Tally the scores of all letters in a word to determine a score for a word.
This score will then be used to sort words in order to choose a candidate for the next attempt.
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Create a scoring vector c(e=1, t=2, a=3 ... z=26)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
letter_freqs <- strsplit('etaoinshrdlcumwfgypbvkjxqz', '')[[1]]
letter_scores <- setNames(1:26, letter_freqs)
score_letters <- function(letters) sum(letter_scores[tolower(letters)])
score_letters(c('h', 'e', 'l', 'l', 'o'))#> [1] 35score_letters(c('z', 'y', 'x', 'x', 'y'))#> [1] 110Glorified regular expressions in a function
The regular expression to find candidate words from a larger list of words evolves with each guess as new letters are discovered or excluded.
To help out with this regex evolution, I wrote a function to wrap a number of common operations starting from a candidate list of words:
- keep only words which have known letters in their exact position.
- Discard words which have letters we know are excluded.
- Discard words which have letter counts are in excess of requirments
- Carefully filter out words where we know particular letters are not correct
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#' Filter words based upon "Wordle" game state
#'
#' @param words character vector of candidate words
#' @param exact single string representing known characters in the word, with
#' '.' used to indicate the letter at this position is unknown.
#' E.g. For a 5 letter word if the 3rd and 4th letters are known to be 'a' and 'c', but
#' all other letters are unknown, then \code{exact = "..ac."}
#' @param excluded_letters string containing letters known to not be in the word
#' @param wrong_spot a character vector the same length as the number of letters
#' in the target word. Each string in this vector represents all letters
#' which are known to be part of the word, but in the wrong spot.
#' E.g. if 'a' has been attempted as the first character, and it exists
#' in the word, but worlde claims it is not yet in the correct position,
#' then \code{wrong_spot = c('a', '', '', '', '')}
#' @param known_count name character vector giving letters and their known counts.
#' E.g. This can be used if it is known definitively that there is only
#' one letter 'e' in the target word, in which case
#' \code{known_count = c(e = 1)}
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
filter_words <- function(words, exact = ".....", excluded_letters = "", wrong_spot = c('', '', '', '', ''), known_count = c()) {
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Build a regex to match the exact case, but exclude any words which
# contain excluded letters, or letters in the wrong spot
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
excluded_letters <- rep(excluded_letters, nchar(exact))
stopifnot(length(wrong_spot) == nchar(exact))
excluded_letters <- paste(excluded_letters, wrong_spot, sep = "")
excluded_letters <- ifelse(nchar(excluded_letters) == 0, '.', paste0("[^", excluded_letters, "]"))
regex <- strsplit(exact, '')[[1]]
regex <- ifelse(regex == '.', excluded_letters, regex)
regex <- paste(regex, collapse = "")
regex <- paste0('^', regex, '$')
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Keep only words which match the exact case, and do not contain excluded
# letters, or letters in the wrong spot
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
words <- grep(regex, words, value = TRUE, ignore.case = TRUE)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Built a vector of all included letters regardless of whether they're in
# the wrong spot or not.
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
included_letters1 <- strsplit(exact, '')[[1]]
included_letters2 <- unlist(strsplit(wrong_spot, ''))
included_letters <- c(included_letters1, included_letters2)
included_letters <- included_letters[included_letters != '.']
included_letters <- sort(unique(included_letters))
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Check that we have all included letters required
# Do this by comparing the sorted letters within each word vs a sorted regex
# e.g. to check for letters 'r' and 'e' in 'rebel'
# grepl('e.*r', 'beerl')
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
if (length(included_letters) > 0) {
sorted_included_letters <- paste(sort(included_letters), collapse = ".*")
split_words <- strsplit(words, '')
sorted_letters <- vapply(split_words, function(letters) {
paste0(sort(letters), collapse = "")
}, character(1))
matching_included_letters <- which(grepl(sorted_included_letters, sorted_letters))
words <- words[matching_included_letters]
}
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# enforce a known count e.g. if it is known that there is only a single
# 'e' then drop words like "rebel" from the list of candidate words
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
split_words <- strsplit(words, '')
for (i in seq_along(known_count)) {
letter <- names(known_count)[1]
count <- known_count[[1]]
match_counts <- vapply(split_words, function(x) {
sum(x == letter) == count
}, logical(1))
words <- words[match_counts]
}
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Re-order words by their score. lowest first.
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
split_words <- strsplit(words, '')
word_scores <- vapply(split_words, score_letters, numeric(1))
words[order(word_scores)]
}Puzzle - What’s my first guess?
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Read a bit list of words that is available on many MacOS/Linux systems
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
words <- readLines("/usr/share/dict/words")
words <- filter_words(words, exact = ".....")
head(words, 20)#> [1] "otate" "tatta" "tenet" "Aotea" "eaten" "enate" "tatie" "teest" "teste"
#> [10] "setae" "tease" "teeth" "theet" "State" "state" "taste" "Tates" "testa"
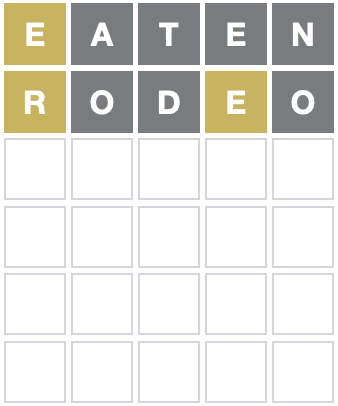
#> [19] "Teton" "arete"Guess eaten
There’s a lot of sillier words in the word list, so I picked out something a
bit more common: eaten

For the next guess:
a,tandnare definitely excluded lettersexcluded_letters = "atn"
- the first
ewas correct but in the wrong spotwrong_spot = c('e', '', '', '', '')
- the second
eis not part of the word at all, which means there can be only 1 e in this wordknown_count = c(e = 1)
words <- filter_words(words, exact = ".....", excluded_letters = "atn",
wrong_spot = c('e', '', '', '', ''), known_count = c(e=1))
head(words, 20)#> [1] "hoose" "hoise" "issei" "osier" "Rhoeo" "serio" "diose" "idose" "loose"
#> [10] "oside" "ohelo" "rodeo" "shies" "Heidi" "helio" "horse" "roleo" "shoer"
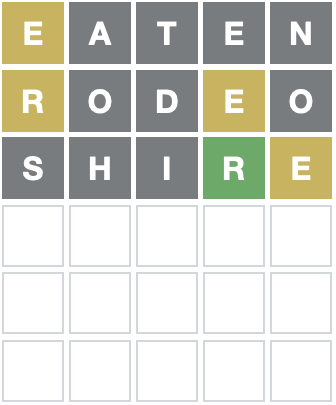
#> [19] "shore" "cooer"Guess rodeo
For the next guess:
oanddshould be added toexcluded_letterseis still not in the correct spot, and we now know thatris part of the word but it should not be in the first position.
words <- filter_words(words, exact = ".....", excluded_letters = "atnod",
wrong_spot = c('er', '', '', 'e', ''), known_count = c(e=1))
head(words, 20)#> [1] "hirse" "shire" "Seric" "cheir" "cress" "swire" "crile" "serif" "shure"
#> [10] "cerci" "ceric" "Circe" "girse" "curie" "ferri" "freir" "Iberi" "meril"
#> [19] "ureic" "crime"Guess shire
For the next guess:
- I now know that
ris the 4th letter in the wordexact = "...r."
s,handiare all excluded from this word.- I now know that
eshould not be the last letter in this word
words <- filter_words(words, exact = "...r.", excluded_letters = "atnodshi",
wrong_spot = c('er', '', '', 'e', 'e'), known_count = c(e=1))
head(words, 20)#> [1] "merry" "ferry" "clerk" "Perry" "perry" "berry" "lyery" "Kerry" "kerry"
#> [10] "querl" "becry" "Jerry" "jerry" "Jewry" "query"Guess merry

words <- filter_words(words, exact = ".erry", excluded_letters = "atnodshim",
wrong_spot = c('er', '', '', 'e', 'e'), known_count = c(e=1))
head(words, 20)#> [1] "ferry" "Perry" "perry" "berry" "Kerry" "kerry" "Jerry" "jerry"Guess ferry

Solved! Now what?
- This might be a nifty Shiny app if anyone felt so inclined.
- Streamline/optimise code - but it runs fast enough for now for it not to be an issue
- Nicer interface - maybe an R6 wrapper to retain state