2 How R executes code
When you execute code in a standard R environment it may be executed in one of two ways:
- AST Interpreter
- Bytecode Virtual Machine (VM)
Which pathway handles execution is dependent on a few things:
- Prior to R 2.13 only AST interpreter was available.
- Newer versions of R have the bytecode VM enabled by default and most code is implicitly executed this way.
- It is possible to create a version of R v4+ with only the AST interpreter enabled. This is currently the case with R/WASM (as of October 2023).
In general, execution with the bytecode VM is faster than with the AST interpreter (see 2019 Tierney Presentation (Tierney 2019)).
The following sections give a high-level overview of these two methods of execution.
2.1 AST Interpreter
The process of execution via the AST interpreter is illustrated below:
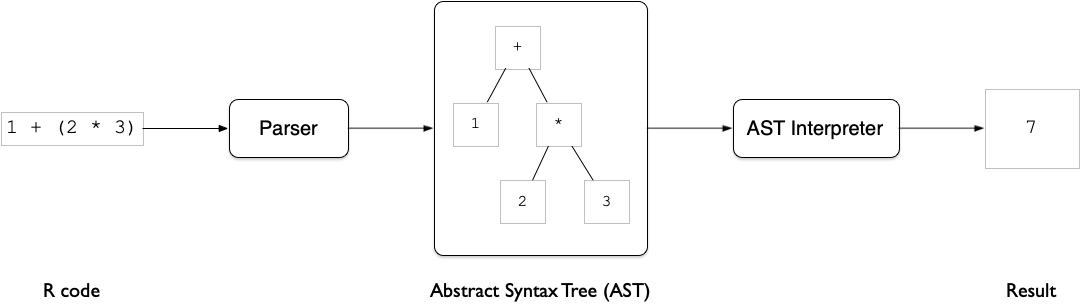
- The parser converts R code to tokens and arranges it as an abstract syntax tree.
- The AST interpreter walks over the nodes in the tree and accumulates results up the tree to produce a result.
A weakness of using an AST interpreter is that each node in the tree is inspected for what needs to be done every single time the code is run - there’s no memory of how a node should be handled.
2.2 Bytecode VM
The process of execution via the bytecode VM is illustrated below:
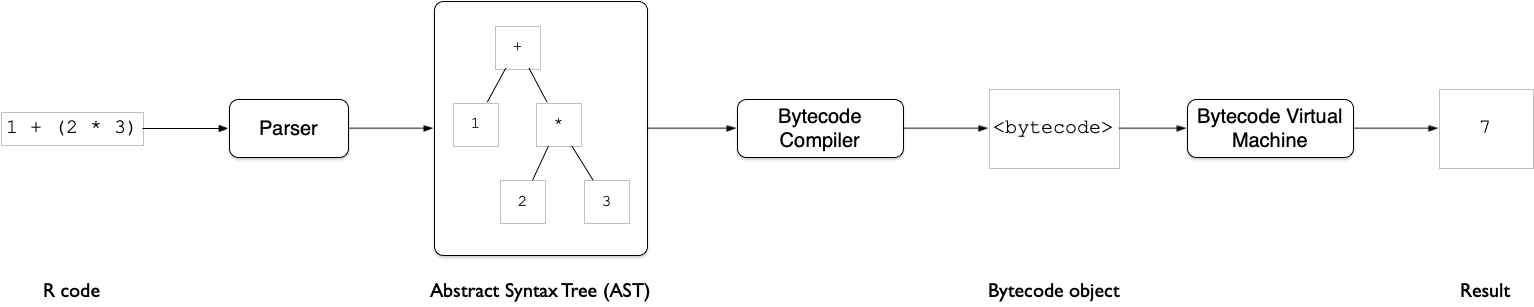
- The first step is the same as the AST interpreter - the parser converts R code to tokens and arranges it as an abstract syntax tree.
- The bytecode compiler (See package
{compiler}) converts the AST to bytecode - essentially an integer vector of instructions with an accompanying list of constants. - The bytecode is evaluated by the bytecode VM
The compilation to bytecode is fast enough such that in most cases the combination of compiling and then executing the bytecode is faster than evaluating the code via the AST interpreter.